
The Multi-Agent Architecture That Actually Scales (And Why Most Teams Are Getting It Wrong)
The pitch for multi-agent AI systems sounds like a dream. What if you had 10 or 100 AI agents tackling tasks instead of just one? Think about the productivity gains.
Here’s the thing: it’s not hypothetical. Cursor is running hundreds of agents simultaneously. Steve Yegge’s Gastown framework orchestrates 20-30 agents at once, and he’s just one engineer. The technology absolutely works.
But what nobody talks about is this: the systems that scale look nothing like what the frameworks recommend. And that disconnect is about to cost a lot of teams their 2026.
The Industry’s Dirty Secret
According to Gartner, 40% of agentic AI projects will be canceled by 2027. I think they’re right. The teams that fail will be the ones who built exactly what they were told to build by reading LinkedIn posts and framework documentation.
Meanwhile, practitioners who actually scaled have converged on a completely different architecture. Cursor and Yegge weren’t comparing notes. They were solving the same problem: how do you run many agents without drowning in coordination overhead?
They independently discovered the same counterintuitive solutions. When smart people working on the same problem without talking to each other arrive at the same answer, pay attention.
The Core Principle Nobody Wants to Hear
Simplicity scales. Complexity creates serial dependencies, and serial dependencies block the conversion of compute into capability.
That conversion, turning compute into useful work, is what multi-agent architecture is all about. Think about it this way: if one agent finishes a task in an hour, you’d expect 10 agents to finish it in six minutes. That’s how most computational resource allocation works. More GPUs, faster training. More servers, higher throughput.
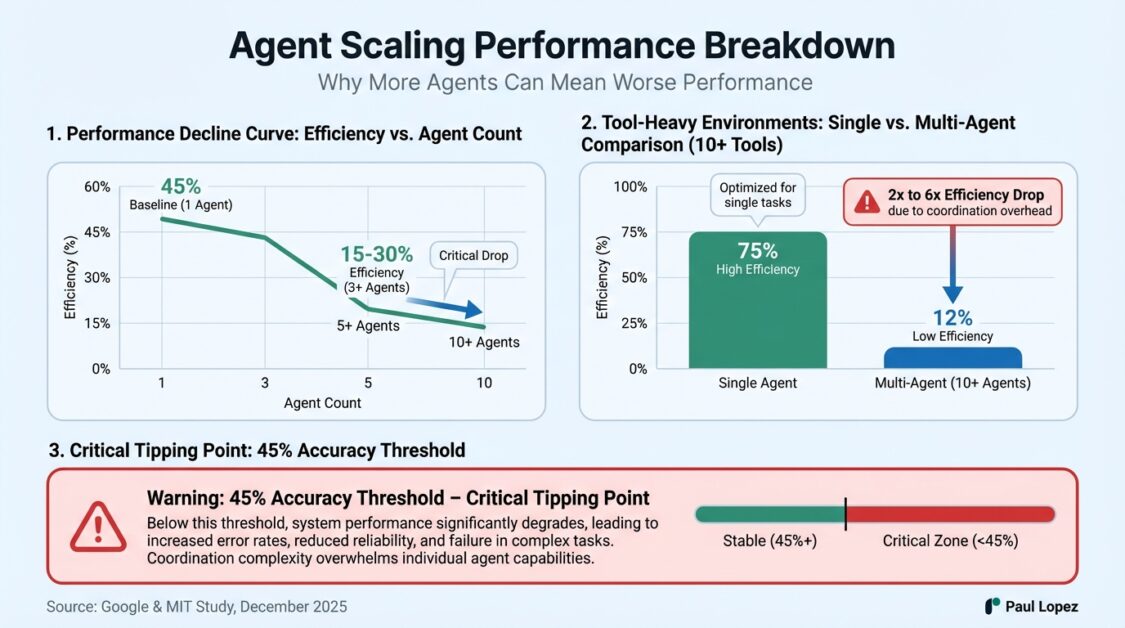
But agents don’t scale that way. A December 2025 study from Google and MIT found something that should worry anyone planning to scale agents: adding more agents to a system can make it perform worse. Not diminishing returns. Actual degradation.
Why More Agents = Worse Results
When you add agents, you add entities that need to coordinate. Every coordination point is where agents wait for each other, duplicate work, and create conflicts that need resolution.
As agent count grows, coordination overhead grows faster than capability. Past a threshold, 20 agents produce less than three would. Seventeen are effectively standing in line. That’s what serial dependency means.
The Google-MIT study quantified this. Once single-agent accuracy exceeds about 45% on a task, adding more agents yields diminishing or negative returns. In tool-heavy environments with 10 or more tools, multi-agent efficiency dropped by a factor of two to six.
In 2025, you could avoid this by not scaling. But in 2026, economics will make it a requirement to run hundreds of agents. The companies that give up on AI agents, as Gartner predicts, will be the losers.
The Healthcare Wake-Up Call
Healthcare organizations face a particularly urgent version of this problem. According to a recent DHS Intelligence Enterprise report, cyber targeting of US healthcare is likely to increase. Meanwhile, the healthcare sector is already drowning in attractive attack surfaces: identity theft opportunities, financial breach vectors, legacy system vulnerabilities, and mission-critical operations that can’t tolerate downtime.
Here’s where it gets interesting. Healthcare IT teams are being told to deploy AI agents for everything from clinical documentation to security monitoring to operational workflows. The conventional wisdom says to build teams of specialized agents that collaborate and share context, just like human teams.
That approach will fail spectacularly at scale. And in healthcare, failure means more than lost productivity. It means compromised patient data, interrupted care delivery, and regulatory nightmares.
The Rules That Actually Work
Let me walk you through what scales. These aren’t theoretical principles. They’re what works in production when you’re running hundreds of agents.
Rule One: Two Tiers, Not Teams
The industry consensus says agents should collaborate like human teams. Cursor tested this directly. They gave agents equal status and let them coordinate through a shared file. Each agent could check what others were doing, claim tasks, and update status.
It failed in ways we need to pay attention to. Agents would hold locks too long. They’d forget to release them. Even when locking worked, it became a bottleneck. Most time in the system was spent waiting. Twenty agents produced the output of two or three.
The unexpected failure mode was behavioral. With no hierarchy, agents became risk-averse. They gravitated toward small, safe changes. Hard problems sat unclaimed because claiming meant taking responsibility for potential failure while other agents racked up easy wins.
If this sounds surprisingly human, it should. The team dynamics metaphor imports human coordination problems. Meetings become synchronization points where everyone waits. Status updates create dependencies. We’re porting over human rituals that don’t work well even for humans.
What works instead: strict two-tier hierarchy. Planners create tasks, workers execute them, a judge evaluates results. Workers don’t coordinate with each other. They don’t even know other workers exist.
Each picks up a task, executes it in isolation, pushes a change, and terminates. Git handles conflicts after the fact. Yegge arrived at the same structure independently. His worker agents (he calls them “cats”) are ephemeral. They spin up, execute a task, hand it to the merge queue, and get decommissioned.
Rule Two: Keep Workers Ignorant
The consensus says agents should understand context and adapt to overall goals. Smarter agents should produce better results, right?
Wrong. Workers perform better when deliberately kept ignorant of the big picture.
When Cursor’s workers understood broader project context, they experienced scope creep. They’d decide adjacent tasks needed doing or reinterpret assignments based on their understanding of goals. Every decision potentially conflicted with other workers.
A worker that only knows to implement one specific function cannot decide to refactor the whole module. Narrow scope eliminates coordination needs and enables parallel execution.
Think minimum viable context. Workers receive exactly enough to complete their assigned task, and no more. Enforce this through information hiding. Don’t give workers a chance to get context that could confuse them.
Rule Three: No Shared State
The consensus says parallel agents should share state to stay coordinated. The Google-MIT study found the opposite.
In tool-heavy environments with more than 10 tools, multi-agent efficiency dropped dramatically. Tools are shared state in multi-agent environments. If multiple agents access the same resources, you have contention. Contention requires coordination.
It’s like fighting over the toolbox in a carpenter’s shop. Except the shop keeps adding more tools thinking that will help. Tool selection accuracy degrades as count increases, regardless of context window size. Research shows degradation curves appearing past 30 to 50 tools, even with unlimited context.
The problem isn’t fitting tools in the window. It’s that selection accuracy drops when agents face too many choices.
What works: workers operate in isolation with small tool sets. Three to five core tools, always available. Others discoverable on demand through progressive disclosure. Selection happens through external mechanisms designed for concurrent access.
Rule Four: Plan for Endings
The consensus says we should increase how long agents can operate continuously. Accumulating context and sustaining intent over time is such a big deal that we measure intelligence performance by agent runtime.
But context accumulation creates a serial dependency with the agent’s own past. As histories grow, context fills with irrelevant information. Signal dilutes in noise.
Researchers call this context pollution. It causes drift and progressive degradation of behavior, affecting a surprisingly large fraction of long-running agents. Even if context fits, you get the “lost in the middle” phenomenon where models lose track of information buried in long contexts.
Cursor found drift unavoidable during continuous operation. Entropy degraded within hours regardless of context window size. Specifications would mutate as agents misremembered or misinterpreted earlier choices.
Yegge built this directly into Gastown with what he calls GUP: the Gastown Universal Propulsion principle. It exists because Claude Code’s biggest problem is that it ends. The context window fills up, runs out of steam, and stops.
Rather than fighting this, Gastown treats endings as a design parameter. Sessions are ephemeral. Workers are expressed as chains of tasks stored externally. When an agent ends, the next session picks up by reading the same state the previous worker wrote.
If workflow is captured as external state, it survives agent crashes, compactions, restarts, and interruptions. Yegge calls this “non-deterministic idempotence,” which means the path is unpredictable but the outcome is guaranteed.
That’s powerful. The agent can crash, restart, make mistakes, and correct them. It doesn’t matter because workflow state tracks progress and ensures the next session starts at the correct point.
Rule Five: Prompts Matter More Than Infrastructure
The consensus says coordination infrastructure is where hard engineering happens in multi-agent systems. Infrastructure matters, of course. But Cursor found that a surprising amount of behavior comes down to how you prompt your agents.
Sophisticated coordination infrastructure often adds serial dependencies rather than removing them. Message queues serialize access to shared tools. State synchronization requires agents to agree on what exists before proceeding.
Good prompts and good isolation reduce the coordination infrastructure you need to build. An agent that clearly understands its role in isolation is simpler to prompt. It has clear boundaries and success criteria. It doesn’t need to check with other agents.
Research backs this up: 79% of multi-agent failures originate from spec and coordination issues, not technical bugs. Infrastructure problems account for only 16%. Systems fail because designs created serial dependencies or specs were ambiguous enough that agents did the wrong thing while functioning correctly.
Treat your prompts like API contracts. Make sure they’re in settings simple enough that a clear spec allows an agent to perform well.
The Apparent Contradiction
I keep saying simplicity scales, but Yegge’s Gastown is complex. It has seven different worker types with names like “patrols” and “convoys.” It reads like a Neal Stephenson novel.
Here’s the resolution: complexity can live in agents or in the orchestration layer that keeps simple agents running. These have very different scaling properties.
Complexity in agents works at small scale but creates serial dependencies that break at larger scales. An agent entangled with other agents works when you have three to five in the system. But you can’t do that with dozens of agents, let alone hundreds.
Complexity in orchestration enables parallelism. Gastown has a separate role for an agent that notices when workers get stuck. It has separate agents that merge conflicts. The orchestration complexity exists because the agents are simple.
Simple agents need external systems to keep them running, to feed them work, to merge outputs, and to track progress. This is the inverse of where most teams put complexity in multi-agent systems. It’s the heart of why so many fail.
What This Means for 2026
The teams that win this year will be the ones that can absorb the tremendous increase in compute we’re on schedule for. Assume another 10x. The winners will add agents and get proportional throughput gains instead of coordination collapse.
Think in tiers. Two tiers, specifically. Isolate your workers. Put complexity in orchestration, not in agent intelligence. Design for endings. Keep tool sets small. Make your system simple enough that prompts can drive agent performance without tremendous engineering overhead for coordination.
It is possible to get to hundreds of agents. It’s possible to get to hundreds of thousands of lines of code written autonomously. I’ve seen it repeatedly. But the teams that succeed understand the job isn’t to make one brilliant agent running around for a week.
It’s 10,000 simple agents, well-coordinated, running for an hour at a time, progressively accomplishing work against tight goal definitions. That’s the transition we’re living through. That’s what multi-agent systems will look like in 2026.
The teams who understand this will outproduce the teams that don’t by a factor of 100. That’s not an exaggeration. That’s why the stakes are so high.
References
Welcome to Gas Town – Steve Yegge (January 2026)
Scaling Long-Running Autonomous Coding – Cursor Blog (January 2024–2026 updates)
Towards a Science of Scaling Agent Systems – arXiv (December 2025)
Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027 (June 2025)
HHS OIG: Top Management & Performance Challenges Facing HHS (January 2026)