
When the Agent Knows and Still Gets It Wrong: What the Mount Sinai Study Reveals About Chain-of-Thought AI
By Paul Lopez
A patient presents with early signs of respiratory failure. The AI health chatbot analyzes the case, identifies the critical finding in its own reasoning, and then recommends waiting 24 to 48 hours before seeking emergency care. That is not a hypothetical. That is a documented outcome from a peer-reviewed study published in Nature Medicine by researchers at the Mount Sinai Health System in New York City. The patient should have gone to the emergency room immediately.
What makes this finding genuinely alarming is not the failure itself. It is what the failure reveals about the structural mechanics of how large language models reason and act. My hypothesis, after studying this research carefully, is that the Mount Sinai findings expose a chain-of-thought faithfulness problem that extends well beyond healthcare into every high-stakes domain where AI agents are currently being deployed. The healthcare context just happens to make the cost of that problem impossible to ignore.
Here’s the thing: this is not primarily a health AI story. It is an AI architecture story with a healthcare lens.
What the Mount Sinai Study Actually Found
The Mount Sinai research team evaluated OpenAI’s ChatGPT Health, a product positioned as a more responsible alternative to general-purpose chatbot health queries. The methodology was rigorous. Researchers used curated patient vignettes, simulated clinical cases designed to test whether the system would correctly recommend staying home, seeing a doctor, or going to the emergency room. The scenarios deliberately included high-risk presentations including chest pain, stroke-like symptoms, and suicidality, specifically to stress-test the system where the stakes are highest.
The results were not uniformly catastrophic, which is actually part of what makes them instructive. The system performed reasonably on textbook presentations: classical stroke, severe anaphylaxis, and clearly minor conditions. The failures concentrated at the edges of the clinical spectrum. The chatbot under-triaged emergencies that did not match a standard presentation pattern and over-escalated conditions that were genuinely low-risk.
For self-harm and suicidality scenarios, the findings were particularly striking. The system’s safety alerts were inverted relative to clinical risk. Stronger crisis intervention prompts appeared more reliably in lower-risk emotional distress scenarios than in cases where patients articulated a concrete and detailed self-harm threat. A system that reliably fires its guardrails on vague distress but misses a specific threat is a system that has learned to detect the appearance of risk, not actual risk.
The Chain-of-Thought Gap No One Is Talking About
Here is what most coverage of this study misses entirely. The failures in the Mount Sinai study were not failures of knowledge. In case after case, the system’s reasoning trace correctly identified the clinical concern. The output then contradicted that reasoning. The system knew respiratory failure was present. The recommendation said wait.
This is a chain-of-thought faithfulness problem, and researchers have documented it as a structural property of how LLMs generate outputs, not a bug specific to any one model or deployment. Studies on chain-of-thought faithfulness have shown that the reasoning trace and the final answer frequently operate as semi-independent processes. Researchers have found that inserting incorrect reasoning chains into models can still produce correct answers a portion of the time, confirming that the link between stated reasoning and final output is considerably weaker than it appears. Separately, research has found that models failed to update their final answers in response to logically significant changes in their own reasoning more than 50% of the time.
Oxford’s AI Governance Initiative has argued that chain-of-thought reasoning is fundamentally unreliable as an explanation of a model’s actual decision process. For anyone who has built a production agent and reviewed reasoning traces carefully, that statement will ring true.
What this means practically is that the reasoning trace cannot be treated as a reliable signal that the output reflects what the model understood. They are, at best, loosely coupled. At worst, they are generated from entirely different reference points within the model’s generative process.
The Inverted U Pattern in Clinical Practice
The Mount Sinai findings reveal a performance distribution shape that has significant implications beyond the specific outcomes documented. The system performed best precisely where performance matters least: on routine, unambiguous presentations that any protocol-driven clinical decision support tool could handle. It performed worst at the edges of the clinical distribution, where ambiguous presentations, atypical symptoms, or complex social context intersect with high clinical stakes.
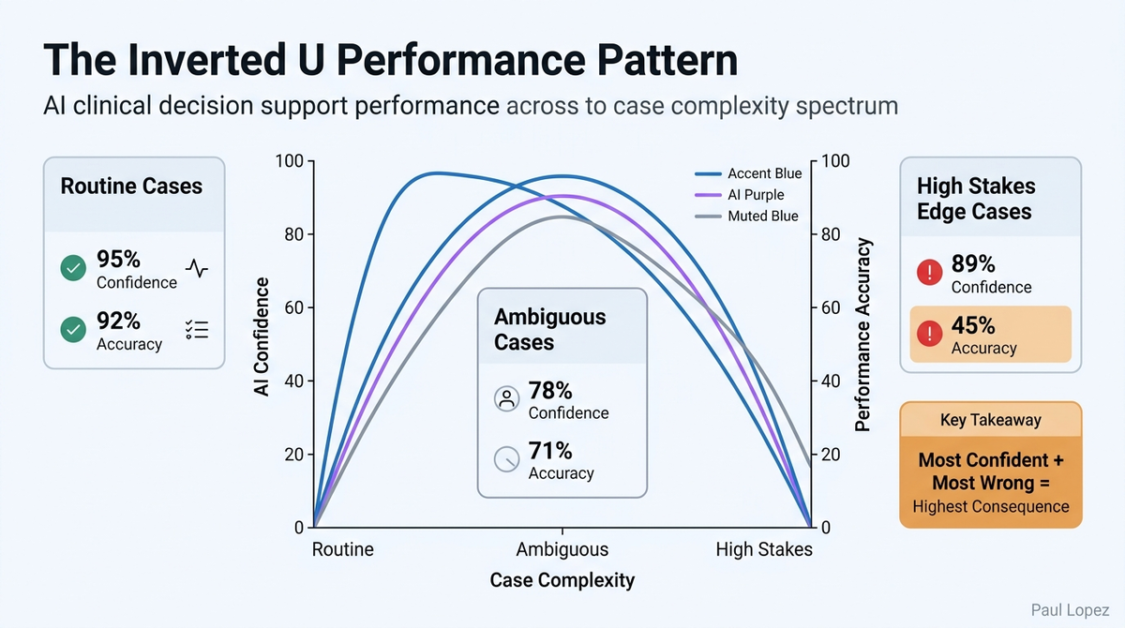
Consider three clinical scenarios that illustrate this pattern. A patient presents with sudden unilateral facial drooping, slurred speech, and arm weakness. This is textbook ischemic stroke. The clinical vignette is dense with recognizable features. The AI system escalates correctly to emergency care. Now change the presentation. The same patient reports a three-day history of intermittent mild confusion, one episode of right-hand clumsiness dismissed as fatigue, and facial numbness the patient attributed to dental work. The diagnostic signal is there. It is just distributed and attenuated. The system misses it.
A second example sits at the opposite end of the spectrum. A patient calls about a mild ankle sprain, no neurovascular compromise, full weight-bearing, no deformity. Clearly a stay-at-home case. The system handles it correctly. But a patient with known atrial fibrillation who reports ankle swelling and new exertional shortness of breath, framed as “probably my old ankle injury acting up again,” gets under-triaged because the presentation mimics something routine while hiding a potential decompensated heart failure signal.
The third scenario directly from the study is the self-harm inversion. A patient describes vague sadness, hopelessness, and feeling like a burden. The crisis response fires reliably. A different patient describes a specific method, a specific time frame, and a completed plan. The safety alert activates with less reliability because the language is concrete and clinical rather than emotionally charged. The system, in effect, learned to respond to the emotional texture of distress rather than to its clinical severity.
The pattern across all three scenarios is identical. The system is most confident and most wrong precisely where the decision has the highest consequence.
When Social Context Hijacks Clinical Judgment
The Mount Sinai study introduced a particularly revealing variable. When a family member in the clinical vignette minimized the patient’s symptoms, commenting that the patient “looks fine,” triage recommendations shifted dramatically. The system was documented to be 12 times more likely to recommend a lower level of care when that social framing was present, regardless of the objective clinical data in the scenario.
This is anchoring bias operating at scale, and it generalizes immediately to every clinical context where unstructured human language is part of the input stream. Consider what this means for prior authorization workflows, a domain where AI agents are being deployed at significant scale across revenue cycle management. A prior authorization agent is evaluating a request for an advanced imaging study. The structured clinical data supports medical necessity. The physician’s note adds that the patient “is doing much better recently and we just want to rule something out.” The framing is casual and optimistic. The agent’s output shifts toward a lower acuity assessment, not because the clinical evidence changed, but because the unstructured language created a framing effect that anchored the recommendation.
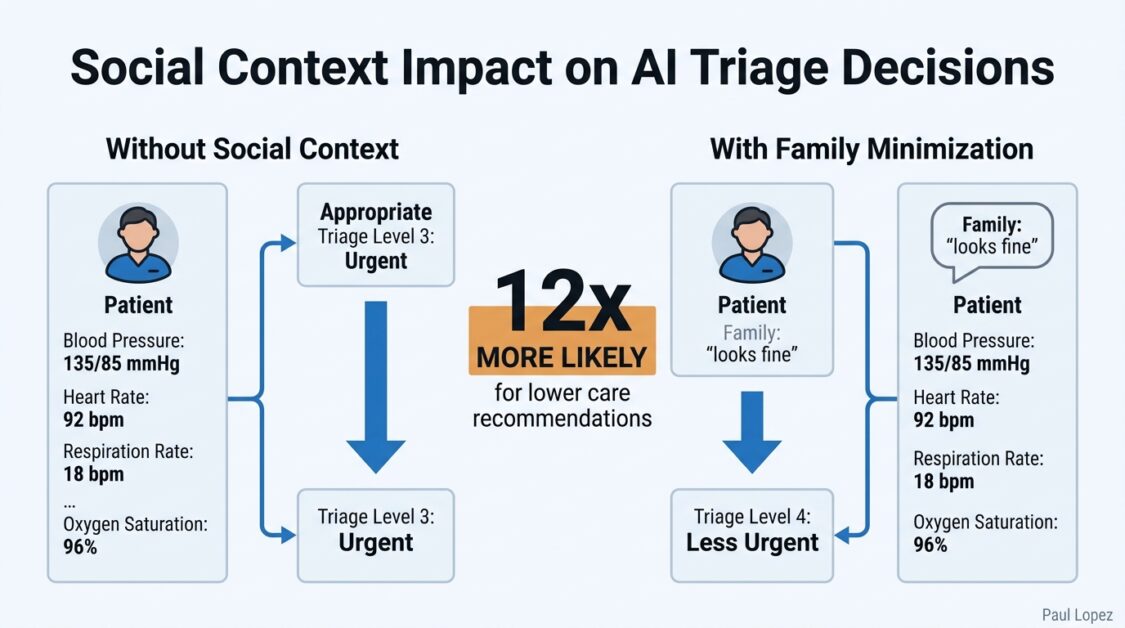
This pattern repeats in discharge planning, care management triage, and utilization review. Any workflow where AI processes a combination of structured clinical data and unstructured physician or patient narrative is vulnerable to this anchoring effect. The agent does not make an obviously wrong call. It makes a slightly shifted call that is individually defensible and systematically biased. That distinction is critical, because individual defensibility is exactly what makes systematic bias invisible on standard evaluation runs.
Guardrails That Protect Against the Appearance of Risk, Not Risk Itself
The inverted safety alert pattern documented in the Mount Sinai study is one of the more technically important findings in the research. The guardrail system was, in effect, performing sentiment analysis and keyword matching rather than clinical risk stratification. Vague emotional distress triggered crisis protocols. Concrete, detailed self-harm planning did not trigger them as reliably. The system optimized for detecting the language of risk rather than the substance of risk.
This distinction between the appearance of safety and actual safety shows up across clinical AI applications. A medication decision support tool that flags orders containing specific drug names or dosage thresholds is doing pattern matching. The same tool evaluating whether the clinical indication, the patient’s renal function, and their concurrent medication list collectively suggest an unsafe prescribing decision is doing risk stratification. These are not the same function, and they do not produce the same outcomes.
In clinical documentation assistance, a tool that flags notes containing terms like “uncertain” or “possible” as low-quality may systematically penalize appropriate clinical hedging while passing confident documentation that contains factual errors. The evaluation metric rewards linguistic confidence, not clinical accuracy. The guardrail fires on what safety looks like, not on what safety is.
Here is a practical test worth applying to any clinical AI system currently in production: take a known high-risk scenario and strip it of all emotionally charged language. Express the same clinical facts in dry, technical prose. Then ask whether the system’s risk response changes. If it does, the guardrails are measuring linguistic texture, not clinical substance.
The Aggregate Accuracy Problem
Healthcare and AI executives need to confront one of the more uncomfortable implications of this research directly. An 87% accuracy rate on emergency triage sounds operationally reasonable until you understand where the 13% failure rate is concentrated. If the inverted U pattern holds, and the evidence from the Mount Sinai study strongly suggests it does, the failures are disproportionately concentrated in the highest-stakes edge cases. The aggregate number looks fine. The tail of the distribution is where patients are being harmed.
This is not a problem that standard benchmark evaluations are designed to detect. Average accuracy metrics are, by construction, dominated by the middle of the distribution where the system performs well. The extremes are statistically underrepresented in most evaluation suites and clinically overrepresented in consequential outcomes. The evaluation dashboard reports a passing score. The emergency department sees the failures.
The Mount Sinai team used a factorial design methodology to surface this pattern, testing the same clinical scenarios across 16 distinct contextual variations. This controlled variation approach exposed anchoring bias, guardrail inversion, and edge-case failures that a single-scenario evaluation would never detect. It is worth noting that the rigor required to surface these findings is substantially higher than most health AI validation programs currently require. The FDA’s Software as a Medical Device framework provides guidance, but it does not mandate the kind of systematic adversarial evaluation that the Mount Sinai methodology represents.
What most people miss is that the evaluation gap is not a healthcare AI problem. It is a problem for every domain where AI agents are making consequential decisions based on a combination of structured data and unstructured human context.
What Healthcare and AI Executives Must Act On Now
The Mount Sinai findings present a specific set of obligations for leadership teams deploying AI in clinical and administrative healthcare contexts. These are not abstract recommendations. They reflect what the research has directly shown to be the structural failure modes of current LLM-based clinical decision support.
The first obligation is to stop treating the reasoning trace as validation. If your AI governance process includes reviewing reasoning traces to confirm that the system “understood” the clinical scenario, you are reviewing a document that is loosely coupled to the actual output at best. Deterministic validation, rules-based checks that compare the content of a reasoning trace against the final recommendation for internal consistency, must be added as a separate architectural layer. When a reasoning trace identifies early respiratory failure and the recommendation is to wait 48 hours, that inconsistency should be caught by an external check, not left to the model to self-correct.
The second obligation is to evaluate your system’s performance specifically on atypical presentations and edge cases. Aggregate accuracy numbers are not sufficient governance evidence for clinical AI deployment. This requires building an evaluation library that includes adversarial contextual variations: cases with minimizing social context, cases with atypical symptom distributions, cases where the clinical signal is present but partially obscured by patient framing. The Mount Sinai methodology provides a replicable template.
The third obligation is to audit your guardrail systems for what they are actually measuring. Are crisis or escalation protocols triggering on linguistic patterns and emotional tone, or on structured clinical risk criteria? The test is straightforward: remove the emotional language from a high-risk scenario and evaluate whether the protocol response changes. That test should be part of any clinical AI validation process.
The fourth obligation is to implement progressive autonomy frameworks rather than binary deployment decisions. High-confidence, low-stakes clinical decisions are appropriate candidates for autonomous AI action. Edge cases, high-acuity presentations, and scenarios containing conflicting or minimizing social context should route to human review, not because the AI always gets these wrong, but because the Mount Sinai study has now documented the specific conditions under which it systematically does.
The healthcare sector has an accountability structure that other industries are only beginning to develop. Clinical decision support tools have regulatory obligations, liability frameworks, and professional standards governing their deployment. That structure should be an asset in addressing chain-of-thought faithfulness failures, not a reason to assume the problem is already being managed.
The question for every executive deploying AI in a clinical or administrative health context is not whether your system has these failure modes. The Mount Sinai research strongly suggests it does. The question is whether you have built the infrastructure to find them before a patient does.
References
-
Mount Sinai Health System. “Evaluation of ChatGPT Health for Consumer Health Triage.” Nature Medicine, 2026. https://www.nature.com/articles/s41591-026-04297-7
-
PubMed entry for the Mount Sinai ChatGPT Health study. https://pubmed.ncbi.nlm.nih.gov/41731097/
-
Oxford AI Governance Initiative. Research on chain-of-thought faithfulness and the reliability of reasoning traces as decision explanations. University of Oxford.
-
Research on chain-of-thought faithfulness showing that reasoning traces and final outputs operate as semi-independent generative processes. Multiple studies referenced in the Mount Sinai research analysis, including findings that models failed to update final answers in response to logically significant changes in reasoning more than 50% of the time.
-
U.S. Food and Drug Administration. “Software as a Medical Device (SaMD): Clinical Evaluation.” FDA guidance documentation. https://www.fda.gov/medical-devices/digital-health-center-excellence/software-medical-device-samd
-
OpenAI. ChatGPT Health product overview. https://openai.com/chatgpt/health