
Why the Smartest AI Teams Are Panic-Buying Compute: The 36-Month AI Infrastructure Crisis Is Here
The global economy has spent three years reorganizing itself around artificial intelligence. Now we’re running out of the compute power to sustain it.
This isn’t your typical supply chain hiccup where lead times stretch from weeks to months. We’re facing the largest supply-demand mismatch in technology history, with AI compute demand growing exponentially while supply remains physically constrained through 2028. The smartest CTOs have already figured this out. They’re not just securing capacity for next quarter; they’re panic-buying infrastructure they won’t need for 18 months because they know it won’t be available when they do need it.
The math is brutal, and the window to act is closing fast.
The Demand Explosion That Nobody Saw Coming
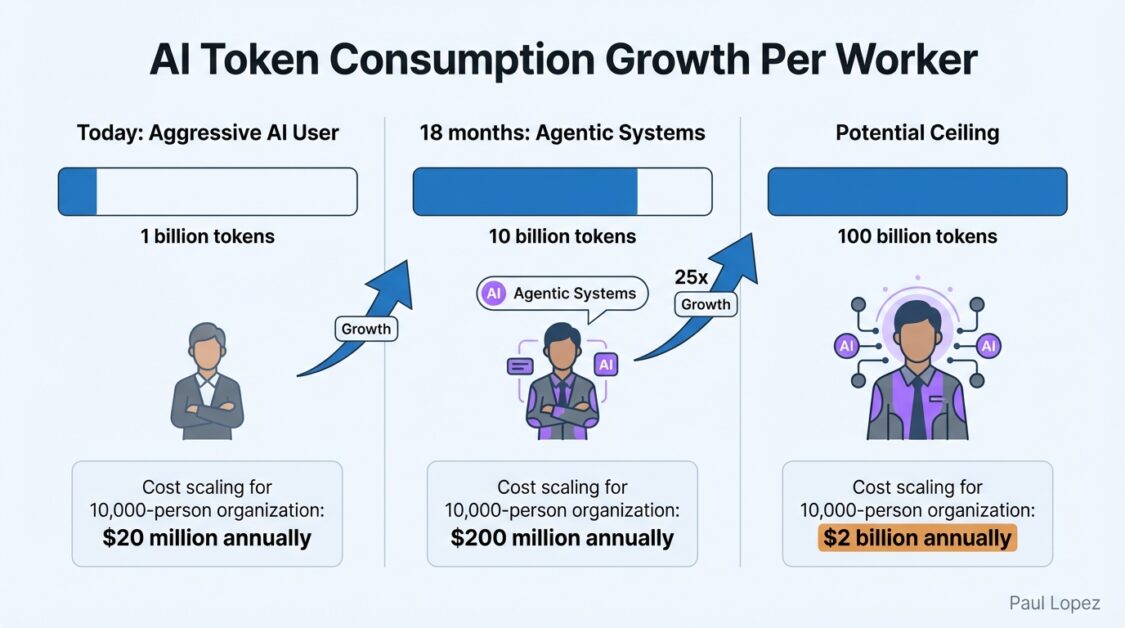
Here’s what enterprise leaders need to understand: current AI consumption represents the floor, not the ceiling. A knowledge worker using AI aggressively today consumes roughly one billion tokens annually. That sounds like a lot until you realize the actual ceiling is closer to 25 billion tokens per worker, representing a 25x increase from current heavy usage.
Three forces drive this acceleration. First, capability unlocks usage. Features that barely worked a year ago now work exceptionally well, and every improvement creates nonlinear demand growth. Second, integration multiplies touchpoints. AI isn’t a standalone tool anymore; it’s embedded across email clients, development environments, and CRM systems. Every integration creates continuous, ambient consumption.
But the real multiplier is agentic systems. Human users have natural rate limits: they type at certain speeds, take breaks, and go home. Agents don’t. An agentic system running continuously could consume billions of tokens daily. A fleet of parallel agents could consume trillions.
Consider a 10,000-person organization at current consumption levels of one billion tokens per worker. That’s $20 million annually at current pricing, expensive but manageable. At 10 billion tokens per worker, which agentic systems could reach within 18 months, the compute bill becomes $200 million. At 100 billion tokens per worker, you’re looking at $2 billion annually.
These calculations assume stable pricing and available capacity. Neither assumption holds.
The Physical Reality of Broken Supply Chains
AI inference is memory-bound. The size of models you can run, execution speed, and concurrent users you can serve all depend on memory. Specifically, high-bandwidth memory for data center inference and DDR5 for edge deployment.
The memory market is fundamentally broken. Server DRAM prices have risen at least 50% through 2025, with projections of another 55-60% increase in Q1 2026. DDR5 64GB RDIMM modules could cost twice as much by end of 2026 as they did in early 2025.
This isn’t a typical cyclical shortage. Structural factors make it different. The three companies controlling 95% of global memory production are shifting toward enterprise segments and AI data center customers. High-bandwidth memory remains a specialized product with SK Hynix dominating production, and output is allocated to NVIDIA, AMD, and hyperscalers. You cannot acquire HBM at any price because it’s simply unavailable.
New DRAM fabrication facilities cost approximately $20 billion and require three to four years to construct. Decisions made today won’t yield additional supply until 2030. There is no near-term supply response.
Below memory lies another constraint: TSMC manufactures the world’s most advanced chips, including NVIDIA’s data center GPUs. Their cutting-edge nodes are fully allocated, with NVIDIA as their largest customer. New facilities in Arizona won’t reach full production until 2028. Essentially all advanced AI chip production runs through TSMC in Taiwan. There is no surge capacity and no meaningful alternative.
The Hyperscaler Conflict Nobody Talks About
Most analyses miss a crucial dynamic: AWS, Azure, and Google Cloud are not neutral infrastructure providers. They are AI product companies that happen to sell infrastructure, competing directly with their enterprise customers.
Google uses its compute allocation to power Gemini. Microsoft uses allocation for Copilot. Amazon uses allocation for AWS AI services. When compute is abundant, this conflict is manageable. When compute is scarce, it becomes zero-sum. Every GPU allocated to enterprise customers is one unavailable for their own products.
Hyperscalers must choose between their products and their customers. They’re choosing their products. Evidence appears in tightening rate limits despite falling API prices and increasing difficulty obtaining allocation commitments for high-volume deployments.
This creates what I call the “Hotel California problem.” You can check out of hyperscaler dependence anytime you like, but you can never leave because they control the scarce resource you need.
Healthcare organizations face particular exposure here. Medical AI applications require sustained, predictable compute access for patient monitoring, diagnostic imaging, and clinical decision support. When AWS throttles your radiology AI because they need capacity for Alexa, patient care suffers. Healthcare CIOs cannot afford to treat compute access as a commodity service anymore.
Why Traditional IT Planning Just Broke
Enterprise IT planning evolved for predictable demand, stable technology, and available supply. None of these assumptions hold.
CTOs applying traditional frameworks will systematically make poor decisions. Consider purchasing 1,000 AI workstations with NPU capabilities at $5,000 each, a $5 million investment with four-year depreciation. By year two, those workstations cannot handle workloads because per-worker consumption has grown 10x. NPUs adequate for code completion cannot sustain agentic workflows consuming billions of tokens. The machines aren’t broken; they’re obsolete.
Sharp CTOs are adapting by following new principles. They’re securing capacity before they need it, shifting vendor conversations from “What’s your price per million tokens?” to “Can you contractually guarantee X billion tokens daily with 99.9% availability?” They’re building routing layers that optimize for cost and preserve optionality by abstracting underlying infrastructure. They’re treating hardware like a consumable, mentally depreciating any AI hardware within two years regardless of accounting treatment.
Most importantly, they’re investing in efficiency as competitive advantage. In supply-constrained environments, every token not consumed is capacity available for additional workloads. Enterprises accomplishing tasks with 50% fewer tokens have twice the effective capacity.
The 36-Month Countdown Starts Now
The global inference crisis isn’t a prediction about what might happen. It’s an observation of current conditions based on existing constraints and price movements already visible in DRAM futures and GPU allocation backlogs.
The demand curve is exponential. The supply curve is flat. The gap will widen for several years.
Enterprises that secure capacity now, build routing layers, treat hardware as consumable, and invest in efficiency will operate through the crisis. Those that don’t will find themselves capacity-constrained and falling behind in the most significant technology transformation in history.
The window for action is open but won’t remain so given current price trajectories. The moment to secure your capacity is now, before panic-buying becomes impossible-buying.
The next 36 months will separate the winners from the footnotes. Which category will your organization occupy?